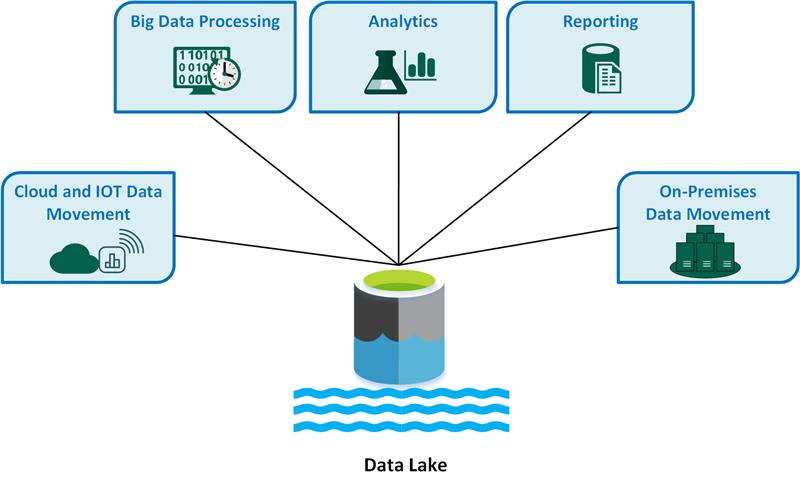
Déployer un Data Lakehouse sur Databricks : Avantages et étapes pratiques
Avec l’essor des architectures hybrides combinant data lakes et data warehouses, le concept de “data lakehouse” s’est imposé comme une solution performante et évolutive. Databricks, leader des plateformes de traitement big data basées sur Apache Spark, propose une implémentation robuste du data lakehouse qui permet d’exploiter au mieux la puissance du cloud.
Dans cet article, nous explorerons les avantages du data lakehouse sur Databricks et détaillerons les étapes pratiques de son déploiement, en mettant l’accent sur un retour d’expérience (REX) des choix d’architecture et les points d’attention à surveiller.
Pourquoi un Data Lakehouse sur Databricks ?
1. Unifier le stockage et l’analytique
Traditionnellement, les data lakes stockent de grandes quantités de données brutes sans structure rigide, tandis que les data warehouses offrent des performances optimisées pour l’analyse mais nécessitent un schéma strict. Le data lakehouse combine ces approches :
-
Stockage scalable et économique d’un data lake (ex. : AWS S3, Azure Data Lake Storage, Google Cloud Storage).
-
Optimisation des requêtes et gouvernance des données d’un data warehouse.
-
Compatibilité avec SQL, machine learning et data science.
2. Performances accrues avec Delta Lake
Databricks repose sur Delta Lake, une couche open-source qui améliore le stockage des données avec :
-
Transactions ACID : Cohérence et fiabilité des données.
-
Time travel : Restauration et audit des données historiques.
-
Optimisation des performances : Z-ordering, compactage automatique.
3. Flexibilité et évolutivité du cloud
Grâce à son intégration native avec AWS, Azure et GCP, Databricks permet de scaler dynamiquement selon la charge de travail, réduisant ainsi les coûts tout en garantissant une haute disponibilité.
Étapes détaillées pour déployer un Data Lakehouse sur Databricks
1. Configurer l’environnement cloud
Avant de commencer, assurez-vous d’avoir :
-
Un compte Databricks (AWS, Azure ou GCP).
-
Un stockage cloud compatible (ex. : S3, ADLS, GCS).
-
Des permissions IAM bien configurées pour gérer les accès aux données (IAM Policies sur AWS, Managed Identities sur Azure, etc.).
-
Un réseau adapté (ex. : VPC sécurisé, Private Link pour éviter le transit des données sur Internet public).
REX & Points d’attention
-
Veillez à bien configurer les permissions IAM pour éviter des erreurs d’accès aux données.
-
Sur AWS, privilégiez les IAM Roles avec des permissions minimales.
-
Activez le chiffrement natif des objets stockés pour assurer la conformité (KMS sur AWS, SSE sur Azure).
2. Créer un cluster Databricks
Un cluster Databricks est l’élément central pour exécuter vos workloads.
-
Accédez à l’interface Databricks et créez un cluster.
-
Sélectionnez un runtime supportant Delta Lake et Apache Spark.
-
Configurez les nœuds de calcul selon vos besoins (auto-scaling recommandé pour optimiser les coûts).
REX & Points d’attention
-
Privilégiez les clusters à court terme (Job Clusters) plutôt que les clusters allumés en permanence (All-Purpose Clusters).
-
Sur AWS, utilisez des instances spot pour réduire les coûts.
3. Déployer Delta Lake et organiser le stockage
-
Activez Delta Lake en définissant le format delta lors de l’ingestion des données :
df.write.format("delta").save("s3://mon-bucket/delta- table/") -
Convertissez des tables Parquet existantes en Delta Lake :
CONVERT TO DELTA parquet.`s3://mon-bucket/parquet- table/`
REX & Points d’attention
-
Structurez bien vos tables Delta (bronze, silver, gold) pour faciliter les transformations.
-
Activez Auto Optimize et Auto Compaction pour éviter la fragmentation excessive.
4. Ingestion et transformation des données
Utilisez Auto Loader pour charger les données en continu :
df = spark.readStream.format(“cloudFiles”) \
.option("cloudFiles.format", "json") \
.load("s3://mon-bucket/raw-data/")
Pour les données en streaming, veillez à bien configurer le checkpointing pour éviter la perte de données.
Nettoyez et transformez les données avec Spark SQL et Delta Lake.
REX & Points d’attention
• Préférez les tables Delta aux tables Parquet pour un meilleur contrôle des mutations de données.
5. Optimisation des performances
• Activez Z-ordering pour améliorer les performances des requêtes :
OPTIMIZE delta.`s3://mon-bucket/delta-table/` ZORDER BY (customer_id)
• Planifiez des tâches d’optimisation automatique avec Databricks Jobs.
REX & Points d’attention
-
L’optimisation Z-ordering est efficace pour les colonnes souvent utilisées dans les filtres WHERE.
-
Planifiez des tâches d’optimisation régulières pour éviter la dégradation des performances.
6. Gouvernance et Sécurité des données
-
Gérez les accès avec Unity Catalog.
-
Activez le chiffrement et la conformité RGPD.
-
Configurez les audit logs pour suivre l’utilisation des données.
REX & Points d’attention
-
Activez l’audit logging pour suivre toutes les modifications de données.
-
Séparez les accès lecture/écriture selon les équipes pour éviter les mauvaises
manipulations.
Conclusion
Déployer un data lakehouse sur Databricks permet aux entreprises de bénéficier d’une architecture flexible, performante et adaptée aux besoins analytiques modernes. Grâce à l’intégration de Delta Lake, à l’optimisation des traitements et à la scalabilité du cloud, cette solution représente un atout majeur pour les organisations cherchant à valoriser leurs données.
En suivant ces étapes et en prenant en compte les retours d’expérience partagés ici, vous serez en mesure de mettre en place un environnement robuste, sécurisé et évolutif pour le traitement et l’analyse de vos données à grande échelle.